需要予測AIの基本的な仕組みとは
需要予測AIとは、過去の販売データや外部要因データを機械学習モデルに入力し、将来の需要量を統計的に推定するシステムです。従来のExcelベースの予測と異なり、数百から数千の変数を同時に処理できる点が最大の強みです。物流業界では、倉庫の在庫最適化や配送計画の精度向上に直結するため、BtoB領域での導入が急速に進んでいます。本章では、需要予測AIがどのような技術要素で構成されているのか、その全体像を解説します。
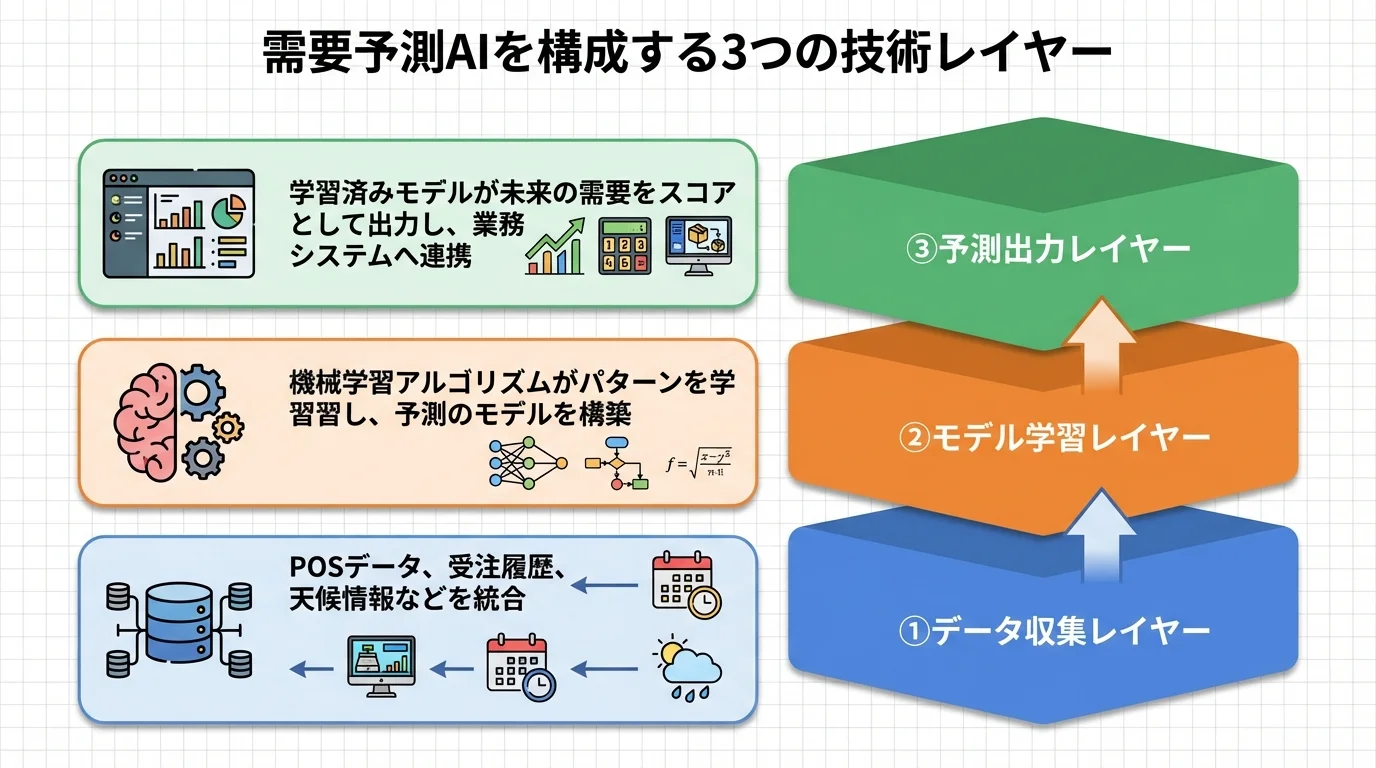
需要予測AIを構成する3つの技術レイヤー
需要予測AIは大きく分けてデータ収集レイヤー、モデル学習レイヤー、予測出力レイヤーの3層構造で成り立っています。データ収集レイヤーでは、POSデータ・受注履歴・天候情報・イベント情報などを統合的に取り込みます。モデル学習レイヤーでは、収集されたデータをもとに機械学習アルゴリズムがパターンを学習し、予測モデルを構築します。予測出力レイヤーでは、学習済みモデルが未来の需要をスコアとして出力し、BIツールやWMSなどの業務システムと連携します。この3層が有機的に連動することで、人手による属人的な予測を超えた高精度な需要予測が実現されます。各レイヤーの品質がシステム全体の予測精度を左右するため、導入時にはそれぞれの設計が極めて重要になります。
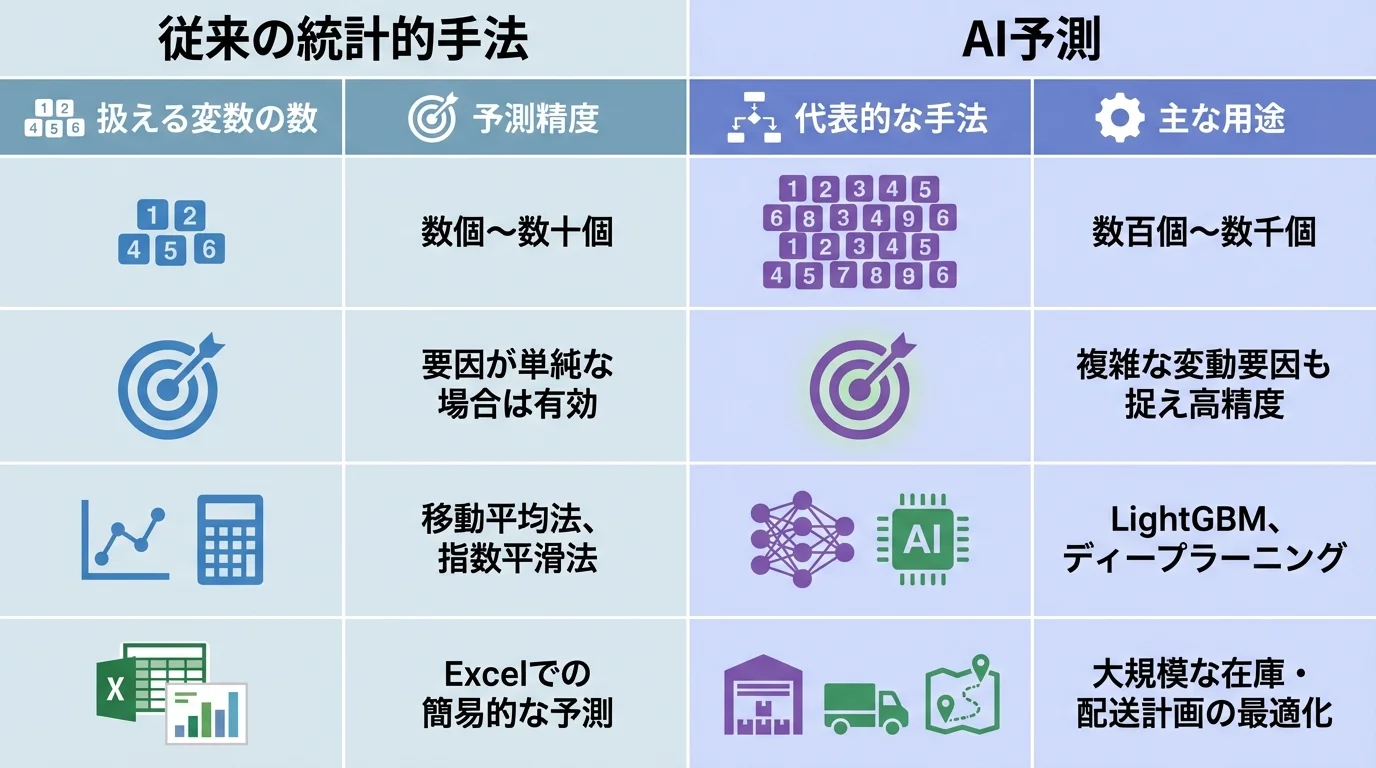
従来の統計的手法とAI予測の違い
従来の需要予測では、移動平均法や指数平滑法といった統計的手法が主流でした。これらの手法は計算が単純でExcelでも実装可能ですが、扱える変数の数が限られるため、需要変動の要因が複雑な場合には精度が低下するという課題があります。一方、AIベースの需要予測では、ディープラーニングや勾配ブースティングなどの手法を用いて、数百の特徴量を同時に学習できます。たとえば、天候・曜日・プロモーション・競合動向・SNSトレンドといった多様な外部要因を自動的に需要予測に反映することが可能です。BtoB物流の現場では、荷主ごとの出荷パターンや季節性が複雑に絡み合うため、AI予測の優位性が顕著に発揮されます。
需要予測AIが物流業界で注目される背景
物流業界で需要予測AIが注目される背景には、ドライバー不足やEC市場の拡大による物流量の変動増加があります。従来の経験則ベースの予測では、急激な需要変動に対応しきれず、過剰在庫や欠品が頻発する課題がありました。需要予測AIを導入することで、日単位・SKU単位での精密な予測が可能となり、倉庫スペースの最適化や配送車両の効率的な配車計画につなげられます。特にBtoB物流では、取引先ごとの発注パターンや業界特有の繁忙期を精度高く予測できるため、リードタイムの短縮やサービスレベルの向上にも直結します。2024年問題をはじめとする業界課題への対応策としても、需要予測AIへの投資が加速しています。
需要予測AIで使われる主要なアルゴリズム
需要予測AIでは、目的やデータの特性に応じて複数の機械学習アルゴリズムが使い分けられます。時系列データに特化したモデルから、非構造化データも扱えるディープラーニングモデルまで、選択肢は多岐にわたります。アルゴリズムの選定はシステムの予測精度に直結するため、自社のデータ特性やビジネス要件を踏まえた適切な判断が求められます。本章では、物流業界の需要予測で特に有効とされる代表的なアルゴリズムを解説します。
LightGBM・XGBoostなどの勾配ブースティング手法
勾配ブースティングは、需要予測AIで最も広く採用されているアルゴリズム群です。中でもLightGBMやXGBoostは、テーブルデータに対して非常に高い予測精度を発揮し、Kaggleなどのデータ分析コンペティションでも常に上位を占めています。これらのアルゴリズムは、複数の弱い決定木を逐次的に組み合わせることで、データ内の複雑な非線形パターンを捉えます。物流の需要予測では、出荷量・気温・曜日・セール時期などの特徴量を一括で処理し、各要因が需要に与える影響度を自動で学習します。さらに、学習速度が速くメモリ効率も良いため、大量のSKUを持つBtoB物流企業でもスケーラブルに運用できる点が大きなメリットです。
LSTMやTransformerによる時系列ディープラーニング
時系列データの長期的な依存関係を捉えるために、LSTM(Long Short-Term Memory)やTransformerベースのディープラーニングモデルが活用されています。LSTMはリカレントニューラルネットワーク(RNN)の一種であり、過去の時系列パターンを記憶しながら将来の需要を予測する能力に優れています。近年では、Transformerアーキテクチャを応用したTemporal Fusion Transformer(TFT)が注目を集めており、複数の時系列データを同時に処理しつつ、どの時点のどの特徴量が予測に寄与しているかを可視化できる解釈性の高さが評価されています。物流業界では、複数拠点の出荷データを統合的に学習させることで、拠点間の相関関係も考慮した高精度な予測が可能になります。
Prophetやアンサンブル手法の実務的な活用
Meta社が開発したProphetは、トレンド・季節性・イベント効果を自動分解する時系列予測ライブラリとして、実務での導入障壁が低い手法です。Prophetはパラメータチューニングが比較的容易であり、データサイエンスの専門知識が限られたチームでも一定の精度を出せる点が強みです。一方、実運用では単一のアルゴリズムに頼るのではなく、複数モデルの予測結果を組み合わせるアンサンブル手法が推奨されます。たとえば、LightGBMによる特徴量ベースの予測とLSTMによる時系列パターンの予測を加重平均することで、個別モデルの弱点を補完し合い、安定した予測精度を実現できます。BtoB物流では需要変動のパターンが取引先ごとに異なるため、アンサンブル手法による柔軟な対応が特に有効です。
需要予測AIに必要なデータと前処理
需要予測AIの精度は、投入するデータの品質と量に大きく依存します。どれほど高度なアルゴリズムを採用しても、入力データに欠損や偏りがあれば予測精度は低下します。物流業界では、社内の基幹システムに蓄積された出荷データに加え、天候・経済指標・業界トレンドなどの外部データを組み合わせることで予測精度を飛躍的に向上させることが可能です。本章では、需要予測AIに必要なデータの種類と、精度を左右する前処理の具体的な手法について解説します。
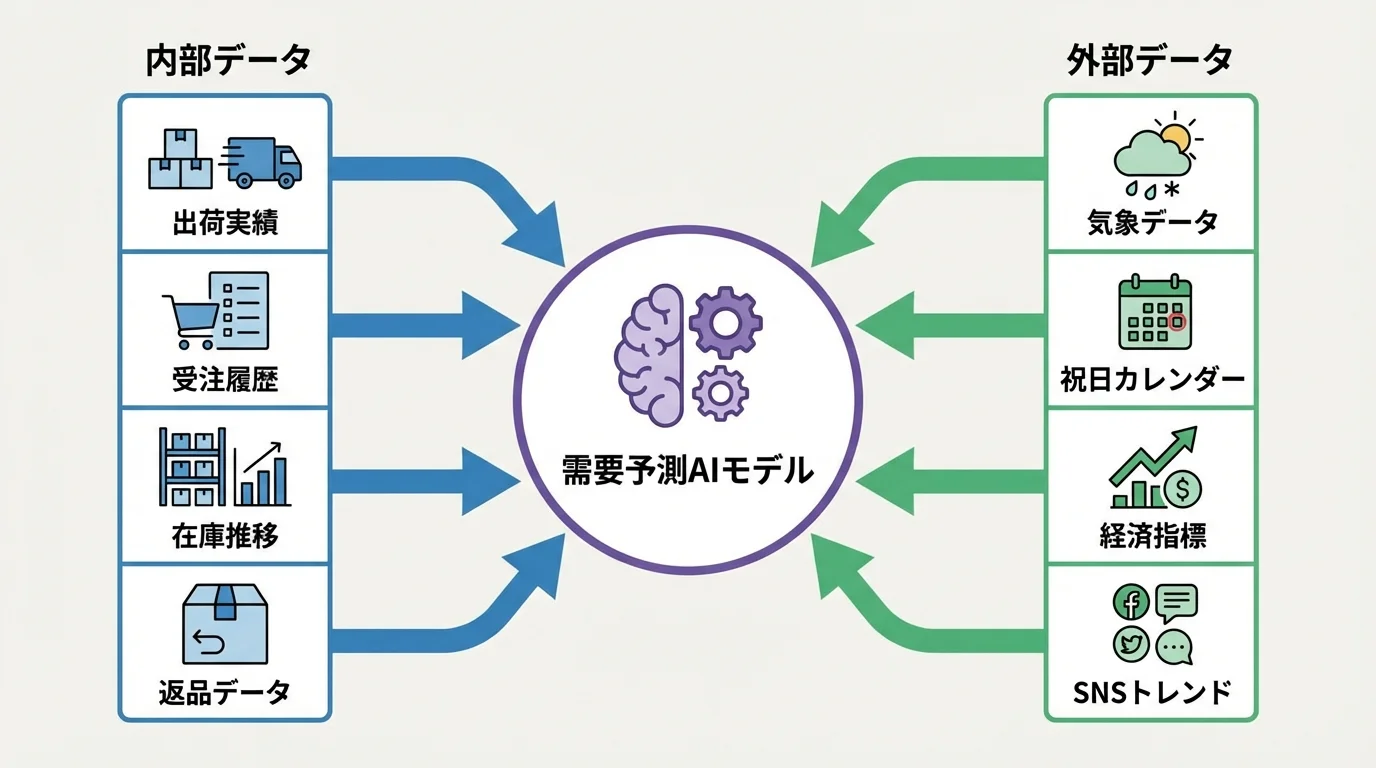
需要予測AIに投入すべき内部データと外部データ
需要予測AIに投入するデータは、大きく内部データと外部データに分類されます。内部データには、過去の出荷実績・受注履歴・在庫推移・返品データ・リードタイム情報などが含まれます。これらは自社の基幹システム(ERP・WMS)から取得可能であり、需要予測の基盤となるデータです。一方、外部データには気象データ・祝日カレンダー・経済指標(GDP・消費者物価指数)・業界ニュース・SNSトレンドなどがあり、需要変動の外的要因を捕捉するために重要です。BtoB物流では、取引先企業の決算期や業界の展示会スケジュールなど、業種特有の外部要因を組み込むことで予測精度が大幅に改善するケースが多く報告されています。データソースの多様化が予測モデルの汎化性能を高める鍵となります。
欠損値処理・異常値検出などのデータクレンジング
収集した生データには、欠損値・異常値・重複データなどが含まれていることが一般的です。データクレンジングはこれらのノイズを除去し、モデルが正しいパターンを学習できる状態にするための重要な工程です。欠損値の処理方法としては、前後の値による線形補間、同曜日の中央値による補完、あるいは欠損フラグを特徴量として追加する手法があります。異常値の検出には、四分位範囲(IQR)法やZスコア法が一般的に用いられ、セールやイベントによる正当な需要増を誤って異常値と判定しないよう、ドメイン知識に基づいたフィルタリングが必要です。物流データでは、システム障害による出荷停止期間や台風による配送遅延など、業務固有の異常パターンを適切に処理することが予測精度の向上に直結します。
特徴量エンジニアリングの具体的手法
特徴量エンジニアリングとは、元データから予測に有効な新たな変数(特徴量)を生成する工程であり、需要予測AIの精度を大きく左右します。代表的な手法として、ラグ特徴量(過去N日間の出荷量)、ローリング統計量(直近7日間の移動平均・標準偏差)、カレンダー特徴量(曜日・月・祝日フラグ・月末フラグ)があります。物流業界では、取引先ごとの発注サイクルを特徴量化したり、過去の同時期における需要パターンとの類似度をスコア化したりすることが効果的です。さらに、ターゲットエンコーディングにより、カテゴリ変数(取引先コード・商品カテゴリ)を需要量との関連性を反映した数値に変換することで、モデルの学習効率を高められます。特徴量の選定と設計は、データサイエンティストとドメインエキスパートの協業で進めることが推奨されます。
需要予測AIの学習プロセスと精度向上の仕組み
需要予測AIは、単にモデルを一度学習させれば完了するものではなく、継続的な学習と精度改善のサイクルを回し続けることで真価を発揮します。初期モデルの構築からハイパーパラメータの調整、検証データによる精度評価、そして本番環境での再学習まで、一連のMLOpsプロセスを確立することが重要です。本章では、モデルの学習がどのように進み、どのような仕組みで精度が向上していくのかを具体的に解説します。
学習データの分割とクロスバリデーション
需要予測モデルの学習では、データを訓練データ・検証データ・テストデータに適切に分割することが精度評価の基本となります。時系列データの場合、ランダムに分割すると未来の情報が学習データに混入する「データリーケージ」が発生するため、時系列分割(Time Series Split)を用いて、常に過去のデータで学習し未来のデータで評価する構成にする必要があります。さらに、予測期間をスライドさせながら複数回の検証を行うウォークフォワード検証を実施することで、特定の期間に依存しない汎化性能の高いモデルを構築できます。BtoB物流では季節変動や取引先の発注パターンが年度によって変化するため、複数年分のデータを用いた検証が精度の信頼性を担保する上で不可欠です。
ハイパーパラメータチューニングの手法
機械学習モデルの性能は、学習率・決定木の深さ・正則化パラメータなどのハイパーパラメータの設定に大きく左右されます。手動でのチューニングには限界があるため、自動化されたチューニング手法が活用されます。代表的な手法として、グリッドサーチ(全組み合わせを網羅的に試行)、ランダムサーチ(ランダムに抽出した組み合わせを試行)、ベイズ最適化(過去の試行結果を基に次の探索点を効率的に決定)があります。特にベイズ最適化を実装したOptunaは、少ない試行回数で最適なパラメータを発見できるため、計算コストの削減に効果的です。BtoB物流の需要予測では、SKU数が数万に及ぶケースもあり、商品グループごとに異なるパラメータセットを管理する仕組みが運用上求められます。
モデルの再学習とドリフト検知の仕組み
需要予測AIを本番環境で運用する際、時間の経過とともにデータの分布が変化し、モデルの予測精度が低下するコンセプトドリフトが発生します。これに対処するため、定期的な再学習(リトレーニング)の仕組みを構築することが不可欠です。再学習の頻度は、日次・週次・月次など業務要件に応じて設定しますが、精度指標(MAPE・RMSE等)を常時モニタリングし、閾値を超えた場合にアラートを発報するドリフト検知の仕組みを併設することが推奨されます。具体的には、PSI(Population Stability Index)やKLダイバージェンスを用いて入力データの分布変化を検出し、精度劣化の予兆を早期に捉えます。BtoB物流では、新規取引先の追加や取引条件の変更が予測精度に影響を与えるため、ビジネス変化に追従できる再学習パイプラインの整備が重要です。
需要予測AIのシステムアーキテクチャ
需要予測AIを企業で本格運用するには、データ収集からモデル推論、結果の業務システム連携までを一貫して支えるシステムアーキテクチャの設計が欠かせません。クラウド基盤の選定、データパイプラインの構築、推論APIの設計、そして既存の基幹システムとの統合方法まで、技術的な検討事項は多岐にわたります。本章では、BtoB物流企業が需要予測AIを実装する際の典型的なシステム構成と、各コンポーネントの役割を解説します。
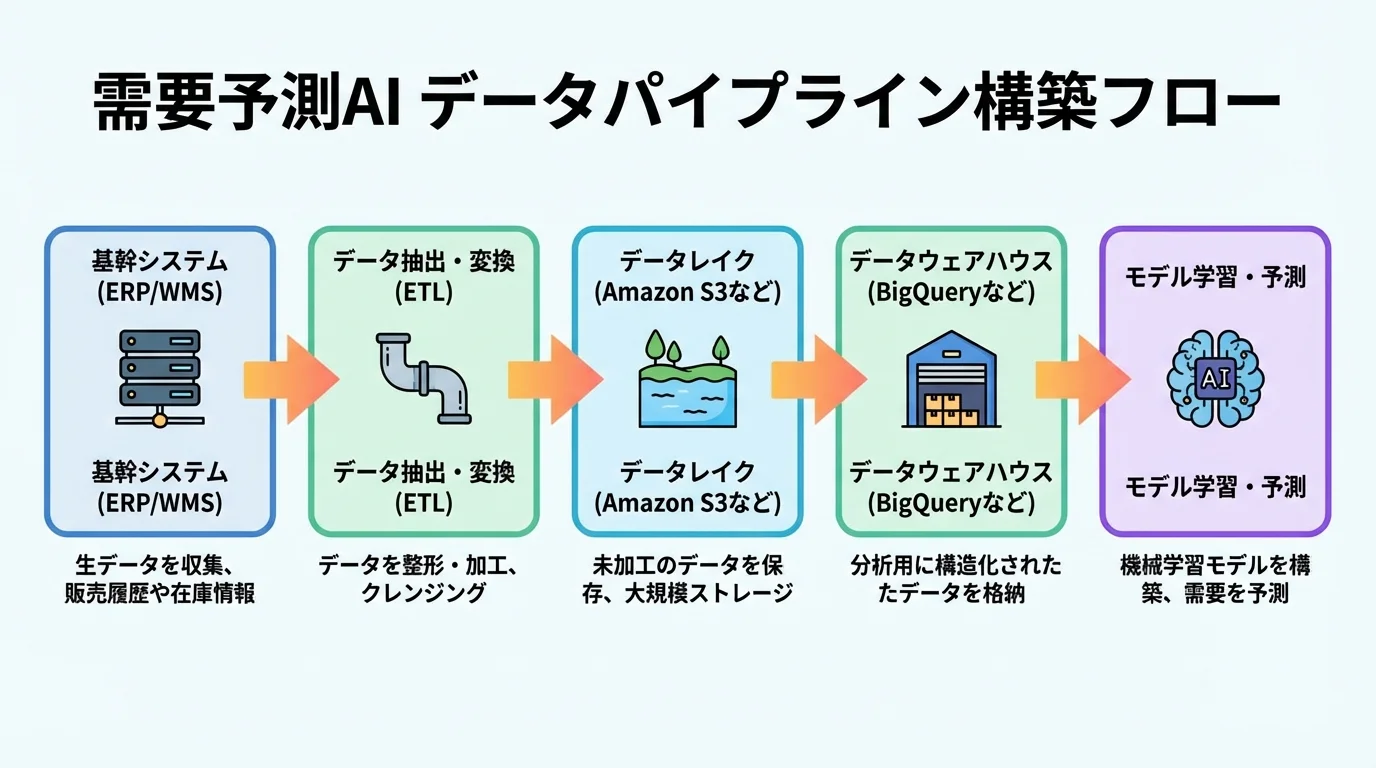
データパイプラインの設計と構築
需要予測AIの基盤となるデータパイプラインは、データの収集・変換・格納を自動化する仕組みです。一般的な構成では、基幹システム(ERP・WMS)からのデータ抽出にETLツール(Apache Airflow・dbt等)を使用し、データレイク(Amazon S3・Google Cloud Storage)に格納します。格納されたデータは前処理・特徴量生成を経てデータウェアハウス(BigQuery・Redshift等)に整理され、モデル学習や推論に利用されます。BtoB物流では、複数の取引先や拠点から異なるフォーマットのデータが送られてくるため、データの正規化と品質チェックを自動化するバリデーションレイヤーの実装が重要です。パイプラインの安定運用には、処理の失敗検知・リトライ機構・データ鮮度の監視などの仕組みが不可欠となります。
モデルサービングと推論APIの設計
学習済みモデルを業務で活用するためには、モデルサービングの仕組みが必要です。モデルサービングとは、学習済みモデルをAPIとしてデプロイし、リアルタイムまたはバッチで予測結果を返却する仕組みを指します。リアルタイム推論では、REST APIやgRPCを通じてリクエストごとに予測値を返し、バッチ推論では定時処理で全SKUの予測結果を一括生成します。物流の需要予測では、日次バッチ推論で翌日以降の需要を予測し、結果をデータベースに格納して配送計画システムに連携するパターンが一般的です。モデルのバージョン管理にはMLflowやSageMaker Model Registryが活用され、A/Bテストによる新旧モデルの性能比較や、問題発生時のロールバックを容易にする運用体制が構築されます。
既存の基幹システム(WMS・TMS)との連携方法
需要予測AIの予測結果を実際の業務改善につなげるためには、WMS(倉庫管理システム)やTMS(配送管理システム)との円滑な連携が不可欠です。連携方式としては、APIベースのリアルタイム連携、ファイル連携(CSV・JSON)によるバッチ連携、データベース共有による直接参照の3パターンが代表的です。BtoB物流では、既存システムのリプレースリスクを最小化するため、まずはCSVファイル連携から開始し、段階的にAPI連携へ移行するアプローチが現実的です。予測結果はダッシュボード(Tableau・Power BI等)でも可視化し、現場担当者が予測値と実績値の乖離を確認しながら最終的な意思決定を行えるようにすることが運用定着の鍵となります。システム連携の設計段階では、データの更新タイミング・エラーハンドリング・権限管理などを事前に定義しておくことが重要です。
需要予測AIの仕組みを理解した上での導入判断
需要予測AIの仕組みを正しく理解することは、自社にとって最適な導入判断を下すための前提条件です。技術的な理解なくベンダー提案を受け入れると、過剰なスペックのシステムを導入してしまったり、逆に必要な機能が不足したりするリスクがあります。本章では、需要予測AIの仕組みを踏まえた上で、導入時に検討すべきポイントや投資対効果の評価方法について解説します。
自社のデータ成熟度に応じた導入ステップ
需要予測AIの導入は、自社のデータ成熟度に応じて段階的に進めることが成功の鍵です。データ成熟度が低い段階(データの一元管理ができていない状態)では、まずデータ基盤の整備から着手し、出荷データの正確な記録と蓄積を最優先とします。次の段階では、統計的手法(移動平均やProphet)による簡易的な需要予測を導入し、予測精度の基準値を確立します。データが十分に蓄積され、品質が安定した段階で初めて、機械学習ベースの本格的な需要予測AIの導入を検討します。BtoB物流企業では、2年以上の日次出荷データが蓄積されていることが、機械学習モデルの有効活用の目安とされています。焦ってAI導入を急ぐのではなく、データ基盤の成熟に合わせた段階的なアプローチが長期的なROI最大化につながります。
ベンダー選定時に確認すべき技術的チェックポイント
需要予測AIのベンダーを選定する際には、技術的な適合性を客観的に評価することが重要です。確認すべきポイントとして、まず使用しているアルゴリズムの種類と選定理由が明確に説明されるかを確認します。次に、モデルの再学習頻度とドリフト検知の仕組みが実装されているかを確認し、長期運用に耐えうるシステムかを判断します。また、予測精度の評価指標(MAPE・RMSE等)とその達成基準が契約上明記されているかも重要な確認事項です。さらに、自社の基幹システムとの連携方式やデータフォーマットの対応範囲、カスタマイズの柔軟性も事前に確認しておく必要があります。BtoB物流では業種特有のデータ特性があるため、同業界での導入実績の有無は信頼性を測る重要な指標となります。
需要予測AIのROI算出と投資対効果の考え方
需要予測AIへの投資判断には、定量的なROI(投資対効果)の算出が不可欠です。主な効果指標としては、在庫回転率の改善(過剰在庫の削減額)、欠品率の低下(機会損失の減少額)、配送効率の向上(車両台数・走行距離の削減額)、人件費の削減(予測業務の工数削減)が挙げられます。一方、コスト側には、システム開発・導入費用、クラウドインフラの運用費用、データ整備にかかる人件費、保守・運用の継続費用が含まれます。一般的に、BtoB物流企業における需要予測AI導入のROIは、在庫関連コストの10〜30%削減、配送コストの5〜15%削減として試算されることが多く、投資回収期間は1〜2年が目安とされています。PoC(概念実証)を実施し、限定的な範囲で効果を検証してから本格導入に進むアプローチがリスクを抑えた投資判断として推奨されます。
まとめ
本記事では、需要予測AIの仕組みについて、基本的な技術構成から主要アルゴリズム、データ前処理、学習プロセス、システムアーキテクチャ、そして導入判断のポイントまでを体系的に解説しました。需要予測AIは、勾配ブースティングやディープラーニングなどの機械学習アルゴリズムを核として、データパイプライン・モデルサービング・業務システム連携の各コンポーネントが一体となって機能するシステムです。BtoB物流企業が需要予測AIを成功させるためには、自社のデータ成熟度を正しく評価した上で段階的に導入を進め、継続的な再学習と精度モニタリングの仕組みを確立することが重要です。仕組みを正しく理解することが、最適なベンダー選定と持続的な運用改善の第一歩となります。