需要予測AIモデルとは?基本概念と種類の全体像
需要予測AIモデルとは、過去の販売データや外部要因を学習し、将来の需要量を高精度に予測するアルゴリズムの総称です。従来のExcelベースの属人的な予測とは異なり、大量のデータからパターンを自動的に抽出できる点が最大の強みです。物流業においては在庫最適化・配送計画・人員配置など幅広い業務改善に直結するため、BtoB領域でも導入が急速に進んでいます。
需要予測AIモデルの定義と従来手法との違い
需要予測AIモデルとは、統計学・機械学習・深層学習のアルゴリズムを活用して将来の需要を定量的に予測する仕組みです。従来の移動平均法やExcelの関数による予測では、担当者の経験や勘に依存する部分が大きく、需要変動への追従が困難でした。AIモデルは数百から数千の変数を同時に処理し、季節性・トレンド・外部要因を自動的にモデルへ組み込みます。これにより、予測精度が従来手法と比較して20〜40%向上するケースも報告されています。特にBtoB物流では取引先ごとの出荷パターンが複雑で、商品カテゴリや配送エリアによる需要の偏りも大きいため、AIモデルの導入効果が顕著に現れます。導入の第一歩として、まず自社のデータ資産を棚卸しすることが推奨されます。
需要予測AIモデルの主要な3分類
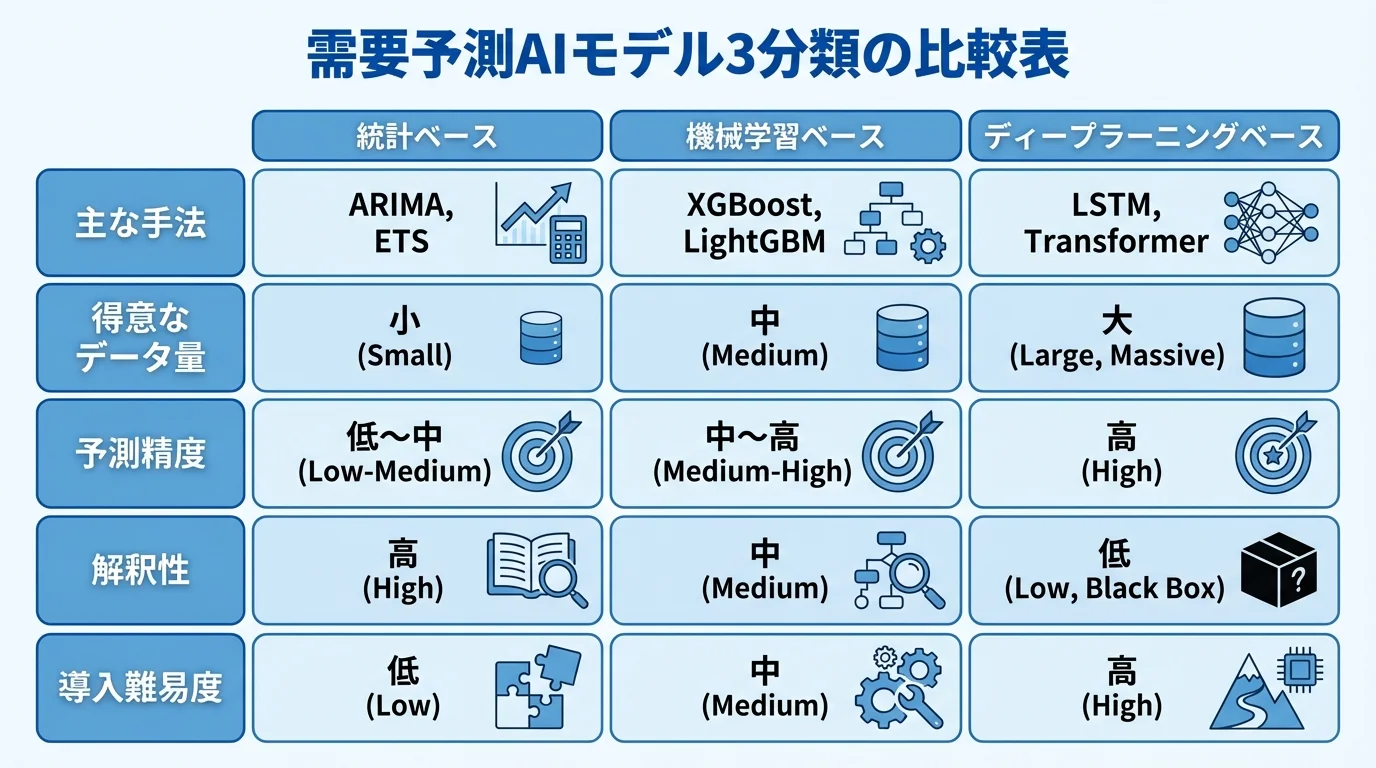
需要予測に用いられるAIモデルは、大きく統計ベース・機械学習ベース・ディープラーニングベースの3種類に分類されます。統計ベースはARIMAや指数平滑法など、時系列データの構造を数学的にモデル化する手法で、少量データでも安定した予測が可能です。機械学習ベースはXGBoostやLightGBMなど、特徴量エンジニアリングを活用して複雑な非線形パターンを捉えます。ディープラーニングベースはLSTMやTransformerなど、大規模データから自動的に特徴を抽出する能力に優れています。それぞれに得意なデータ規模・予測期間・精度特性があり、自社の課題やデータ環境に応じた最適な選択が極めて重要です。近年ではこれら複数の手法を組み合わせたアンサンブルアプローチも注目されています。
物流業における需要予測AIモデルの活用領域
物流業では需要予測AIモデルが在庫管理・配送計画・倉庫運営の3領域で特に効果を発揮します。在庫管理では過剰在庫と欠品の両方を削減し、キャッシュフローの改善に直結します。配送計画では地域別・時間帯別の出荷量予測に基づき、車両台数や配送ルートの最適化が可能になります。倉庫運営ではピッキング作業量の事前予測により、繁忙期の人員配置を最適化できます。BtoB物流企業では、荷主ごとの出荷予測精度を高めることで3PL契約の競争力向上にもつながっており、経営戦略としても重要性が増しています。さらに、返品率の予測やリードタイムの最適化など、サプライチェーン全体の効率化にも需要予測AIの応用範囲が広がっています。
統計ベースの需要予測モデル(ARIMA・指数平滑法)
統計ベースの需要予測モデルは、時系列データの構造を数学的に記述する古典的かつ信頼性の高いアプローチです。ARIMAモデルや指数平滑法(ETS)は解釈性が高く、少量のデータでも安定した予測が可能なため、需要予測AI導入の第一歩として多くの企業が採用しています。データサイエンティストでなくても理解しやすく、経営層への説明が容易な点もBtoB企業での導入を後押ししています。
ARIMAモデルの仕組みと物流での適用シーン
ARIMA(自己回帰和分移動平均)モデルは、過去の値の自己相関と移動平均を組み合わせて将来を予測する時系列モデルです。データの定常性を前提とし、差分変換によりトレンドを除去した上でモデル化します。物流業では月次・週次の出荷量予測や、比較的安定した需要パターンを持つBtoB取引先への納品量予測に適しています。パラメータ(p, d, q)の設定には専門知識が必要ですが、Auto-ARIMAライブラリを活用すれば自動的に最適なパラメータを探索できます。Pythonではpmdarimalibやstatsmodelsといったライブラリで簡単に実装可能です。ただし、急激な需要変動やイベント要因の取り込みには限界があるため、外部変数を加えたSARIMAXへの拡張も検討すべきです。
指数平滑法(ETS)の特徴とメリット
指数平滑法は、直近のデータほど大きな重みを与え、過去に遡るほど影響を減衰させる予測手法です。単純指数平滑法・Holt法(トレンド対応)・Holt-Winters法(季節性対応)の3段階があり、データの特性に応じて使い分けます。物流業では季節性のある商品の入出庫予測にHolt-Winters法が広く活用されています。ARIMAと比較して計算コストが低く、リアルタイム更新にも対応しやすい点がメリットです。また、予測区間の算出が容易なため、安全在庫の設定にも直接活用できます。平滑化パラメータの調整により、需要の急変に対する応答速度と安定性のバランスを制御できる柔軟性もあります。BtoB物流企業が最初に導入するモデルとして最も実績が豊富な手法の一つです。
統計モデルの限界と次のステップ
統計ベースのモデルは解釈性と安定性に優れる一方、複数の外部要因を同時に考慮する能力に限界があります。例えば天候・競合の動向・経済指標・プロモーション施策など、需要に影響を与える多数の変数を統合的にモデル化することは困難です。また、非線形な需要パターンやデータ量が増加した場合にも精度が頭打ちになりやすい傾向があります。商品のライフサイクル変動や突発的なイベントへの対応力も弱点と言えます。統計モデルで予測精度のベースラインを確立した後、機械学習モデルへステップアップするアプローチが実務では効果的です。統計モデルの予測結果を機械学習の特徴量として組み込むハイブリッド手法も、近年BtoB企業で注目されています。
機械学習ベースの需要予測モデル(XGBoost・LightGBM)
機械学習ベースの需要予測モデルは、多数の特徴量を活用して複雑な需要パターンを高精度に捉える手法です。特にXGBoostやLightGBMなどの勾配ブースティング手法は、Kaggle等のデータサイエンスコンペティションでも圧倒的な実績を誇り、企業の実務でも採用が拡大しています。統計モデルでは捉えきれなかった非線形パターンや変数間の交互作用を学習できる点が、BtoB物流の需要予測精度を大きく向上させます。
XGBoostによる需要予測の仕組みと強み
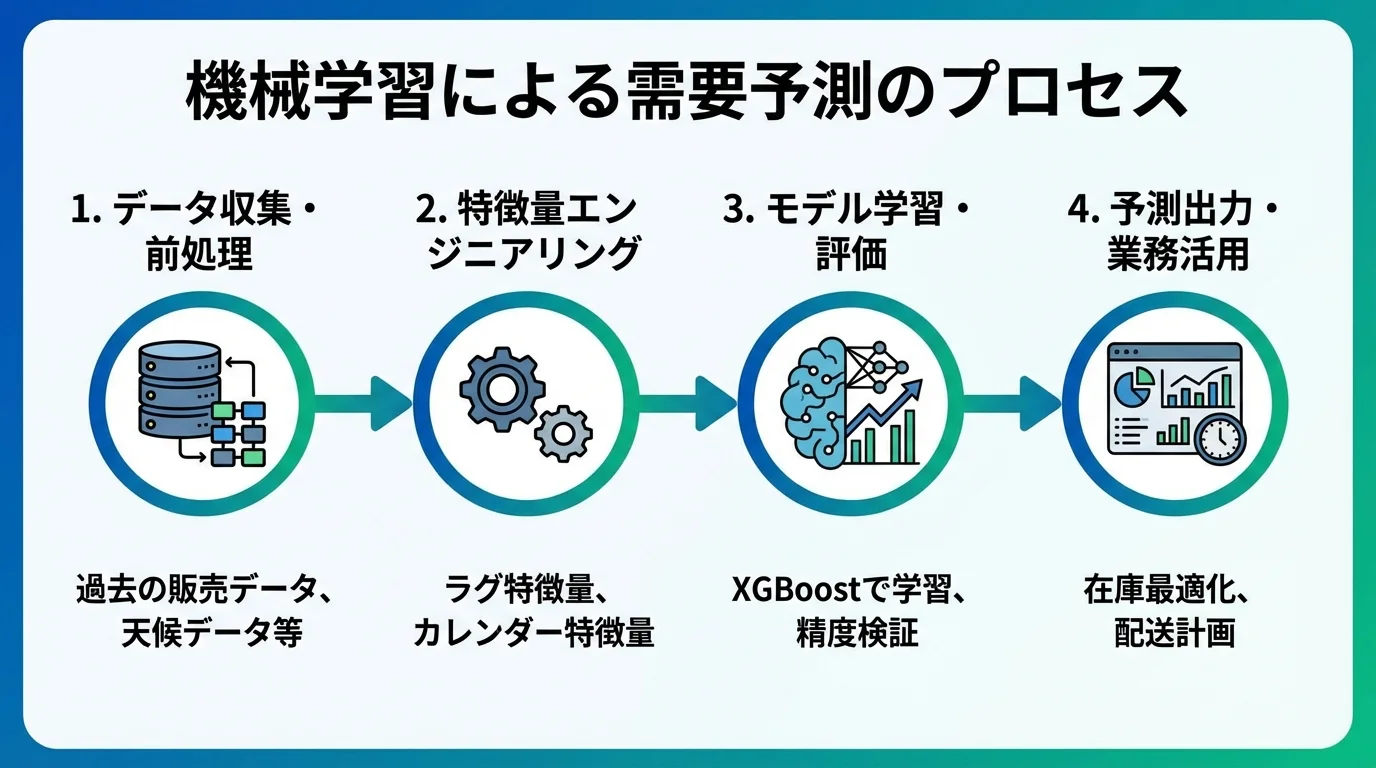
XGBoost(eXtreme Gradient Boosting)は、複数の弱い決定木を逐次的に組み合わせ、予測誤差を段階的に改善する勾配ブースティングアルゴリズムです。需要予測では過去の販売データに加え、曜日・祝日・天候・取引先属性・商品カテゴリなどの特徴量エンジニアリングが精度向上の鍵となります。正則化パラメータ(L1・L2)により過学習を抑制し、欠損値の自動処理にも対応するため、実務データとの相性が良好です。物流業では荷主ごとの出荷量予測や倉庫別の入庫量予測に活用されており、統計モデル比で15〜30%の精度向上が報告されている事例もあります。さらに、特徴量の重要度を数値化できるため、需要に影響を与える要因の分析にも役立ちます。
LightGBMの高速処理と大規模データへの対応
LightGBMはMicrosoft Researchが開発した勾配ブースティングフレームワークで、Leaf-wise成長戦略とヒストグラムベースの分割により、XGBoostと同等以上の精度を大幅に短い学習時間で達成します。数百万行規模のデータセットでも高速に学習できるため、SKU数が膨大なBtoB物流企業の需要予測に特に適しています。カテゴリカル変数のネイティブサポートにより、取引先コード・商品コード・配送拠点などをエンコーディングなしでそのまま投入できる利便性もあります。GPU対応やカスタム損失関数の定義も可能で、ビジネス要件に合わせた柔軟なモデル構築が実現します。メモリ使用量もXGBoostと比較して少なく、限られた計算リソースでも高速に学習を回せる点がBtoB企業の実務環境で高く評価されています。
特徴量エンジニアリングの実践ポイント
機械学習モデルの予測精度を左右する最も重要な要素が特徴量エンジニアリングです。時系列の需要予測では、ラグ特徴量(過去N日・N週の実績値)、ローリング統計量(移動平均・移動標準偏差)、カレンダー特徴量(曜日・月・四半期・祝日フラグ)が基本となります。物流業固有の特徴量としては、取引先の業種・規模・過去の発注頻度、配送エリアの人口動態、季節イベント(お中元・お歳暮等)なども有効です。さらに目的変数の対数変換やBox-Cox変換で分布を正規化し、外れ値の影響を抑制する前処理も精度向上に寄与します。特徴量の重要度分析を定期的に実施し、不要な変数を除外することでモデルの汎化性能を維持できます。
ディープラーニングによる需要予測モデル(LSTM・Transformer)
ディープラーニングベースの需要予測モデルは、大規模かつ複雑なデータから自動的に特徴を抽出し、高度な時系列パターンを学習できる最先端のアプローチです。特にLSTMやTransformerアーキテクチャは長期的な依存関係を捉える能力に優れ、従来の手法では困難だった複雑な需要変動の予測を可能にします。データ量が豊富なBtoB物流企業において、さらなる予測精度の向上が期待されています。
LSTMモデルの構造と時系列予測への適用
LSTM(Long Short-Term Memory)は、長期的な時系列依存関係を記憶・忘却するゲート機構を持つリカレントニューラルネットワークです。入力ゲート・忘却ゲート・出力ゲートの3つが連携し、需要データの長期トレンドと短期変動を同時に学習します。物流業では数カ月〜1年先の中長期需要予測に強みを発揮し、季節性が複雑に絡み合う商品群の予測に適しています。実装にはTensorFlowやPyTorchのフレームワークを利用し、エンコーダ・デコーダ構造を採用することでマルチステップ予測にも対応できます。ただし、学習データが数千件以下の場合は過学習リスクが高く、統計モデルや機械学習モデルの方が安定した精度を示すケースもあります。
Transformerモデルと最新の時系列予測技術
Transformer はSelf-Attention機構により、時系列データの任意の時点間の関係性を並列に学習できるアーキテクチャです。LSTMが逐次処理であるのに対し、Transformerは並列処理が可能なため学習速度が大幅に向上します。需要予測の分野ではTemporal Fusion Transformer(TFT)やInformerなどの派生モデルが高い精度を記録しています。TFTは変数の重要度を自動的に可視化する機能を持ち、予測根拠の説明性にも優れています。BtoB物流では複数の荷主・商品・拠点を横断した需要予測にTransformerモデルが活用され始めており、従来のLSTMと比較して5〜15%の精度向上が確認された報告もあります。
ディープラーニングモデル導入の実務的な注意点
ディープラーニングモデルは高い予測性能を持つ一方、導入・運用にはいくつかの課題があります。まず、十分な学習データ量が必要です。一般的にLSTMでは最低でも数千件、Transformerでは数万件以上のデータポイントが推奨されます。次に、GPU環境の整備や計算コストの問題があり、クラウドGPUサービスの活用が現実的な選択肢です。ハイパーパラメータのチューニングも複雑で、学習率・バッチサイズ・エポック数・ドロップアウト率など多数の設定が精度に影響します。BtoB物流企業がディープラーニングを導入する際は、まず機械学習モデルでベースラインを確立し、精度向上の余地がある領域にのみ段階的に適用するアプローチが費用対効果の観点から推奨されます。
需要予測AIモデルの選び方と評価指標
需要予測AIモデルの選定においては、単純な予測精度だけでなく、データ量・運用体制・ビジネス要件を総合的に評価する必要があります。適切な評価指標を設定し、複数のモデルを比較検証することで、自社に最適なモデルを特定できます。特にBtoB物流では予測誤差が在庫コストや配送効率に直結するため、ビジネスインパクトに基づいた評価基準の設計が重要です。
主要な予測精度評価指標(MAE・RMSE・MAPE)
需要予測モデルの精度評価には複数の指標が用いられます。MAE(平均絶対誤差)は予測値と実績値の差の絶対値の平均であり、外れ値の影響を受けにくい安定した指標です。RMSE(二乗平均平方根誤差)は大きな誤差に対してペナルティが大きく、欠品リスクを重視する場合に適しています。MAPE(平均絶対パーセント誤差)は誤差を割合で表すため、異なるスケールの商品間で比較可能です。物流業では需要量のスケールが商品によって大きく異なるため、MAPEが広く使われますが、需要がゼロに近い商品ではMAPEが不安定になる点に注意が必要です。ビジネス目標に応じて複数の指標を併用することが推奨されます。
データ量・更新頻度に基づくモデル選定基準
最適なモデルはデータの特性によって大きく異なります。データ量が1,000件未満の場合は統計モデル(ARIMA・ETS)が安定した精度を発揮し、過学習のリスクも低い傾向にあります。1,000〜10,000件では機械学習モデル(XGBoost・LightGBM)が特徴量の活用により優位性を示します。10,000件以上のデータが蓄積されている場合は、ディープラーニングモデルの検討価値が高まります。更新頻度も重要な判断基準で、日次更新が必要な場合はLightGBMのような高速なモデルが適しています。BtoB物流企業では、まず統計モデルでベースラインを構築し、データ蓄積に応じて段階的にモデルを高度化するロードマップを設計することが成功の鍵です。
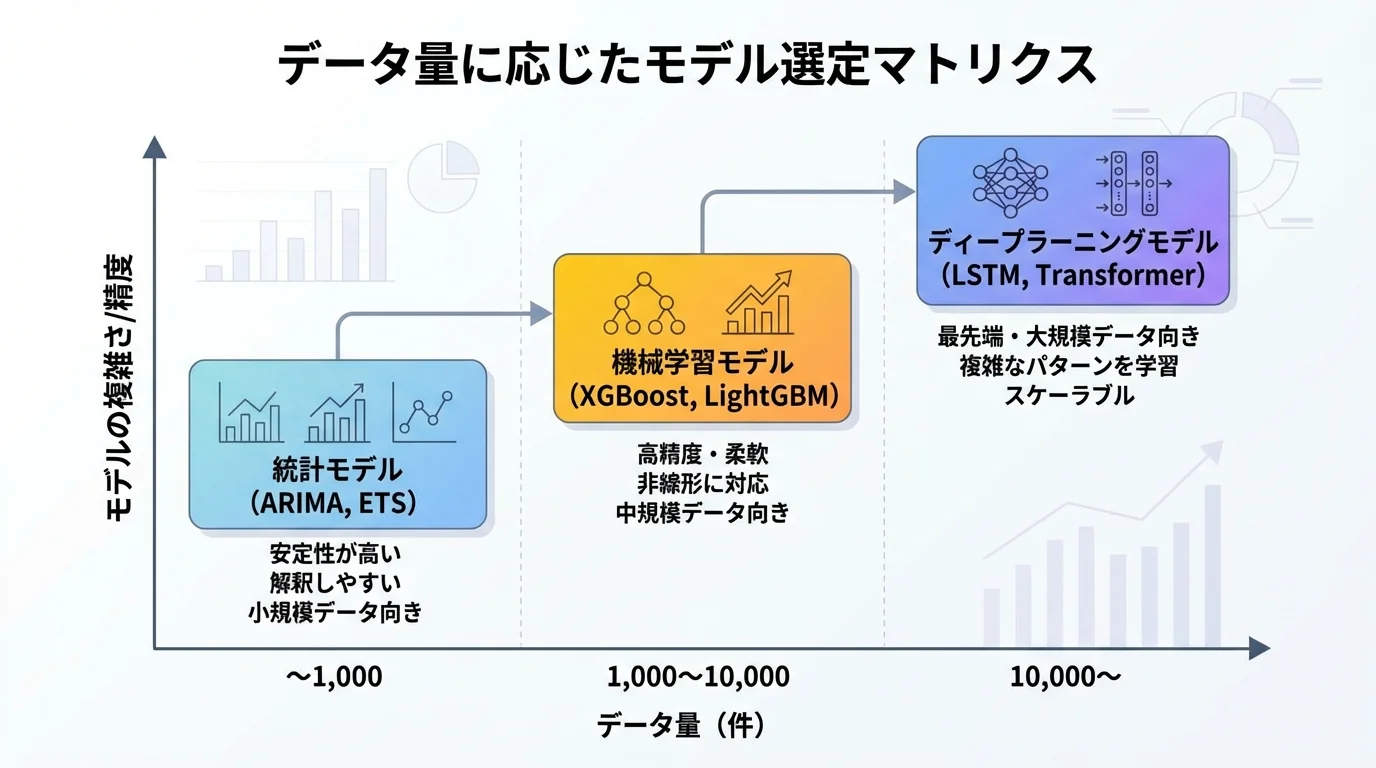
複数モデルの比較検証とアンサンブル手法
実務では単一モデルに依存するのではなく、複数のモデルを並行して検証し、最良のモデルを選定するプロセスが不可欠です。バックテスト(過去データでの検証)を行い、時系列の特性を考慮したウォークフォワード検証により汎化性能を評価します。検証期間の設定は、少なくとも季節性の1サイクル以上をカバーすることが望ましいです。さらに、異なるアルゴリズムの予測結果を組み合わせるアンサンブル手法は、単一モデルを上回る安定した精度を実現できます。代表的な手法として、加重平均アンサンブルやスタッキング(メタ学習)があります。物流業では需要パターンが商品カテゴリや取引先によって異なるため、セグメントごとに最適なモデルを割り当てるマルチモデル戦略も有効です。
需要予測AIモデルの運用と精度維持の実践手法
需要予測AIモデルは導入して終わりではなく、継続的な運用・監視・改善のサイクルを回すことで初めてビジネス価値を持続的に創出できます。データドリフトへの対応、モデルの再学習スケジュール、業務プロセスとの統合など、運用フェーズ特有の課題を事前に設計することが、BtoB物流企業における需要予測AI活用の成否を分けるポイントとなります。
モデルの精度監視とデータドリフト対策
運用開始後にモデルの予測精度が徐々に低下する現象をデータドリフトと呼びます。需要パターンの変化・新規取引先の追加・市場環境の変動・商品ラインナップの入れ替わりなどが原因で、学習データと現実のデータ分布が乖離するために発生します。対策として、予測精度のモニタリングダッシュボードを構築し、MAEやMAPEの推移を日次・週次で可視化することが重要です。精度が閾値を下回った場合に自動アラートを発報する仕組みを整備し、迅速な再学習トリガーとして機能させます。BtoB物流では季節要因や取引先の業績変動の影響が大きいため、四半期ごとの精度レビュー会議を設けて運用改善に反映する体制が推奨されます。
再学習戦略とMLOpsパイプラインの構築
モデルの精度を維持するためには、定期的な再学習の仕組みをMLOpsパイプラインとして自動化することが不可欠です。再学習の頻度は、需要の変動周期やデータ更新頻度に応じて設定します。週次で出荷データが更新される物流企業であれば月次の再学習が一般的ですが、需要変動が激しい領域では週次再学習も検討すべきです。パイプラインにはデータ取得・前処理・学習・評価・デプロイの各ステップを自動化し、モデルバージョン管理も組み込みます。新旧モデルのA/Bテストを自動化し、精度が改善した場合のみ本番環境に反映するカナリアデプロイも有効です。クラウドサービスのAWS SageMakerやGCP Vertex AIを活用すれば、BtoB物流企業でも比較的少ない工数でMLOpsパイプラインを構築できます。
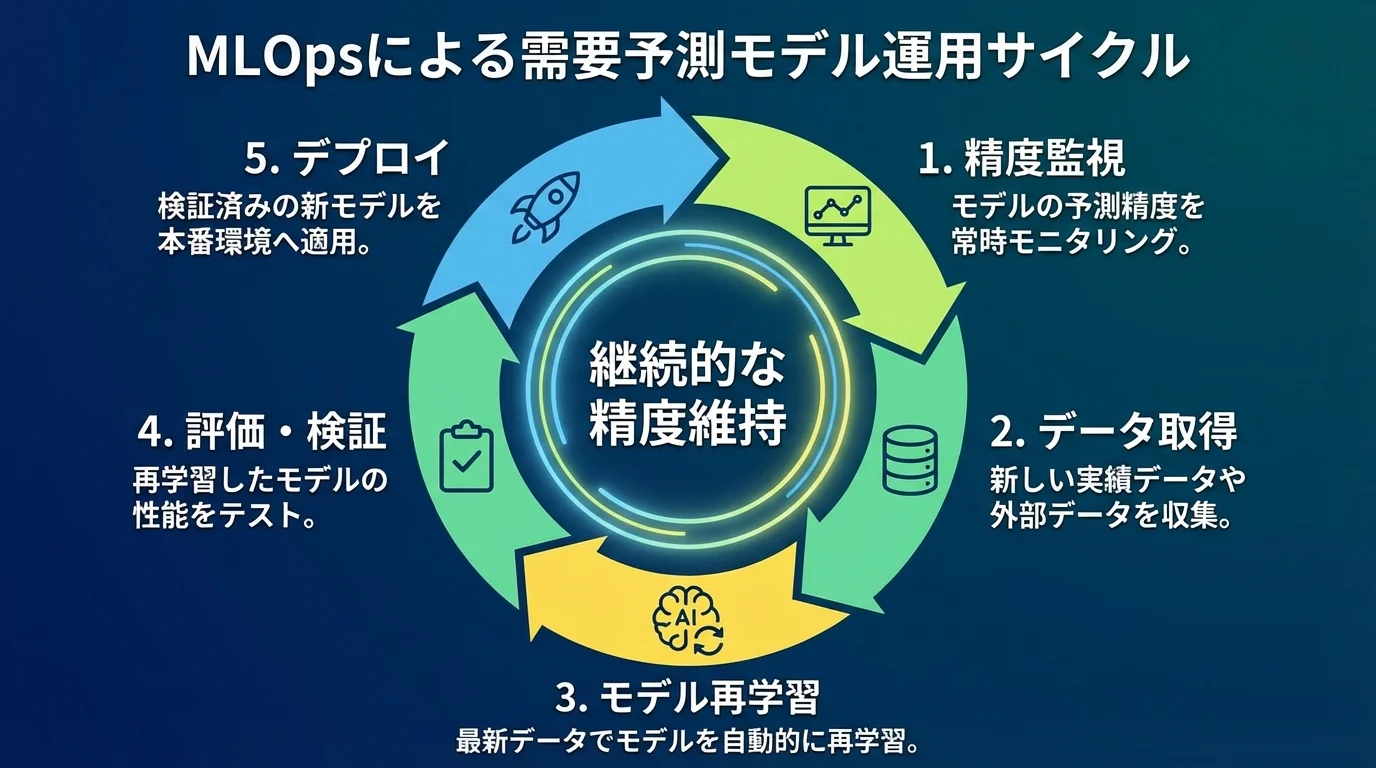
需要予測結果の業務プロセスへの統合方法
需要予測AIモデルの導入効果を最大化するには、予測結果を既存の業務プロセスにシームレスに統合する設計が重要です。具体的には、予測値をWMS(倉庫管理システム)やTMS(配送管理システム)にAPI連携し、在庫補充の自動発注や配車計画の自動生成に活用します。ただし、完全自動化をいきなり目指すのではなく、まずは予測結果を現場の判断材料として提示するアドバイザリー型からスタートし、信頼性が確認された後に自動化範囲を拡大するステップを踏むべきです。BtoB物流では荷主との契約条件や納期制約もあるため、予測ベースの自動化にはビジネスルールのガードレールを設定し、異常値検知時には人間の判断を介在させる設計が実務上有効です。
まとめ
需要予測AIモデルは、統計ベース(ARIMA・指数平滑法)、機械学習ベース(XGBoost・LightGBM)、ディープラーニングベース(LSTM・Transformer)の3つに大別され、それぞれデータ量・精度・運用コストのバランスが異なります。自社の課題やデータ環境に応じて最適なモデルを選択し、段階的に高度化していくアプローチが成功の鍵です。導入後は精度監視・再学習・業務プロセスとの統合を継続的に実施し、需要予測AIを物流DXの中核として活用することで、在庫最適化・配送効率化・コスト削減を実現できます。